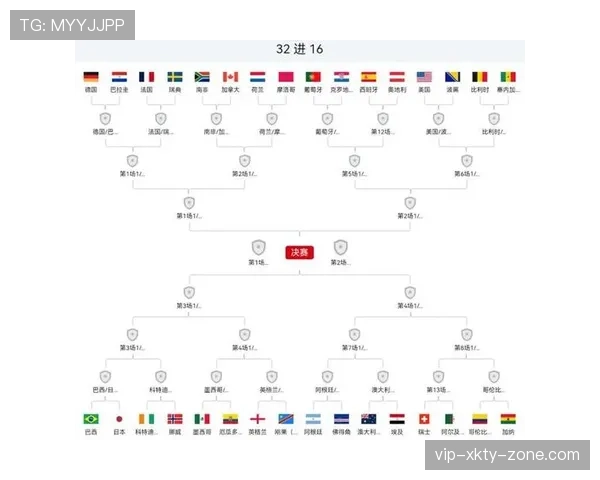
数据模型预测L组最终排名
随着世界杯L组赛事临近尾声,各类数据模型开始基于已有比赛结果、球队历史表现、球员状态及对手强度等因素,对小组最终排名进行动态预测。当前主流模型普遍将葡萄牙列为小组头名的最大热门——他们在前两轮展现出稳定的攻防体系,C罗虽年龄增长但关键战仍有决定性作用,加上布鲁诺·费尔南德斯与莱奥等中生代球员状态火热,整体胜率被估算在70%以上。

韩国队则成为模型中最不确定的一极。尽管首轮爆冷逼平强敌,但次轮面对乌拉圭时暴露了中场控制力不足的问题。部分高级别算法(如FiveThirtyEight的SPI模型)给予其约45%的出线概率,但若末轮对阵葡萄牙无法抢分,极可能因净胜球劣势被挤出局。值得注意的是,韩国队近三届世界杯均有小组出线记录,这种“大赛韧性”在纯数据模型中往往难以量化,也成为预测偏差的潜在来源。
乌拉圭的情况则呈现两极分化。传统Elo评分系统对其防守能力给予高度评价,但进攻端乏力——两场比赛仅打入一球,令多数模型将其出线概率压至30%以下。然而,若末轮大胜加纳且韩国不胜,凭借相互战绩优势仍有机会逆袭。这种“小分依赖型”路径在蒙特卡洛模拟中约占12%的样本比例,虽概率不高却不可忽视。
至于加纳,几乎所有模型已将其排除在晋级行列之外。即便末轮取胜,也需同时满足其他三队极端赛果才能理论出线。不过,非洲球队在世界杯上素有“搅局者”传统,一旦放手一搏打出高比分,仍可能打乱整个小组的积分格局。数据模型虽能捕捉趋势,却难以完全模拟足球赛场上的情绪变量与临场变数。
总体来看,当前预测共识指向葡萄牙第一、韩国第二的格局,但误差区间显著大于其他小组。这不仅反映出L组竞争的胶着xingkong程度,也提醒我们:在世界杯这样的舞台上,数据是参考,而非判决。真正的排名,仍要由绿茵场上的90分钟来书写。